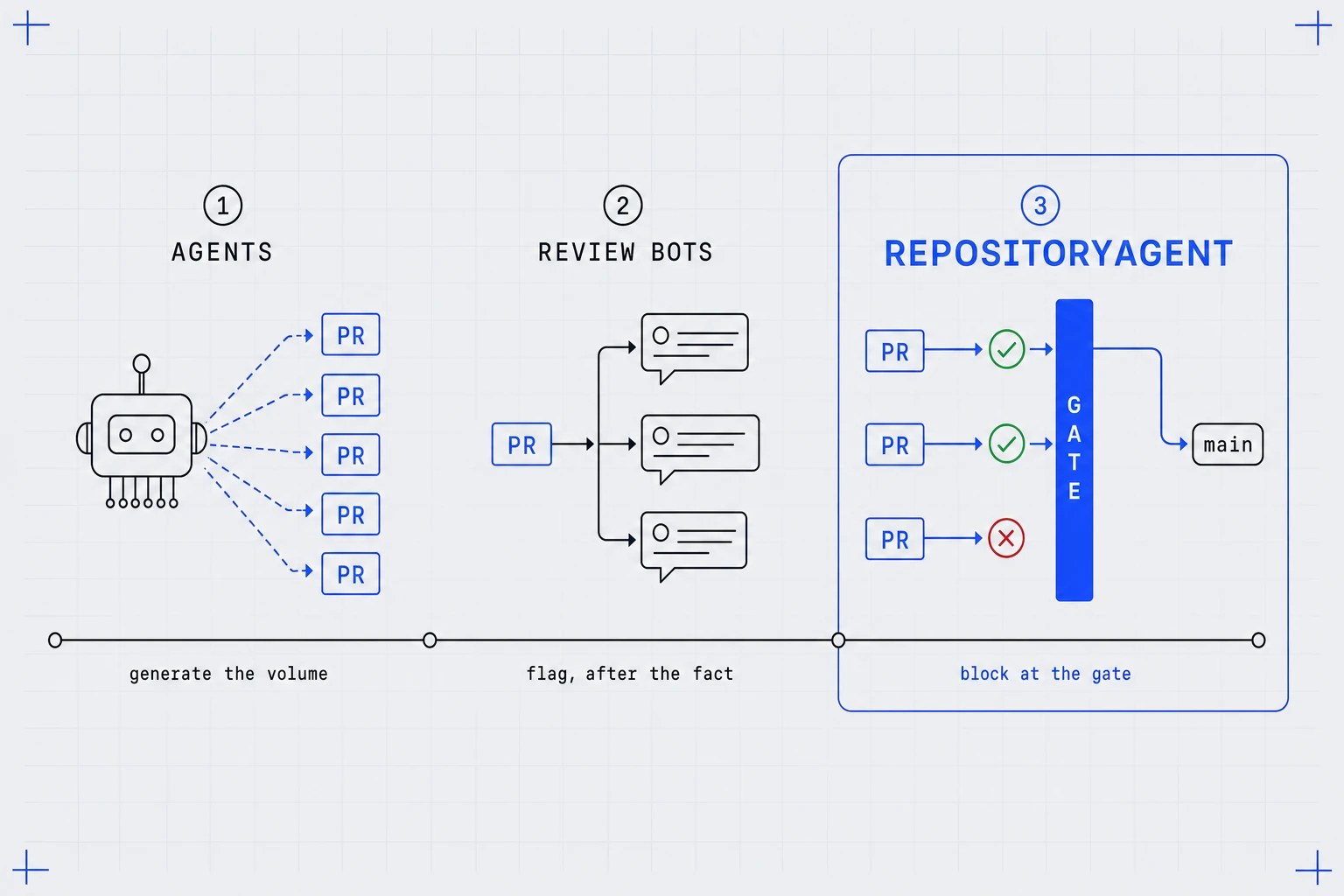
Don't trust the agent. Trust the gate.
You can't code-review your way out of agent volume, and you can't prompt your way to a guarantee. But you already own the one thing that is a guarantee: the pipeline every commit flows through. Harden it once, and it holds the line against humans and agents alike.
If an anti-pattern can't pass your pipeline, then an AI's code can't land it either.
The tooling already exists
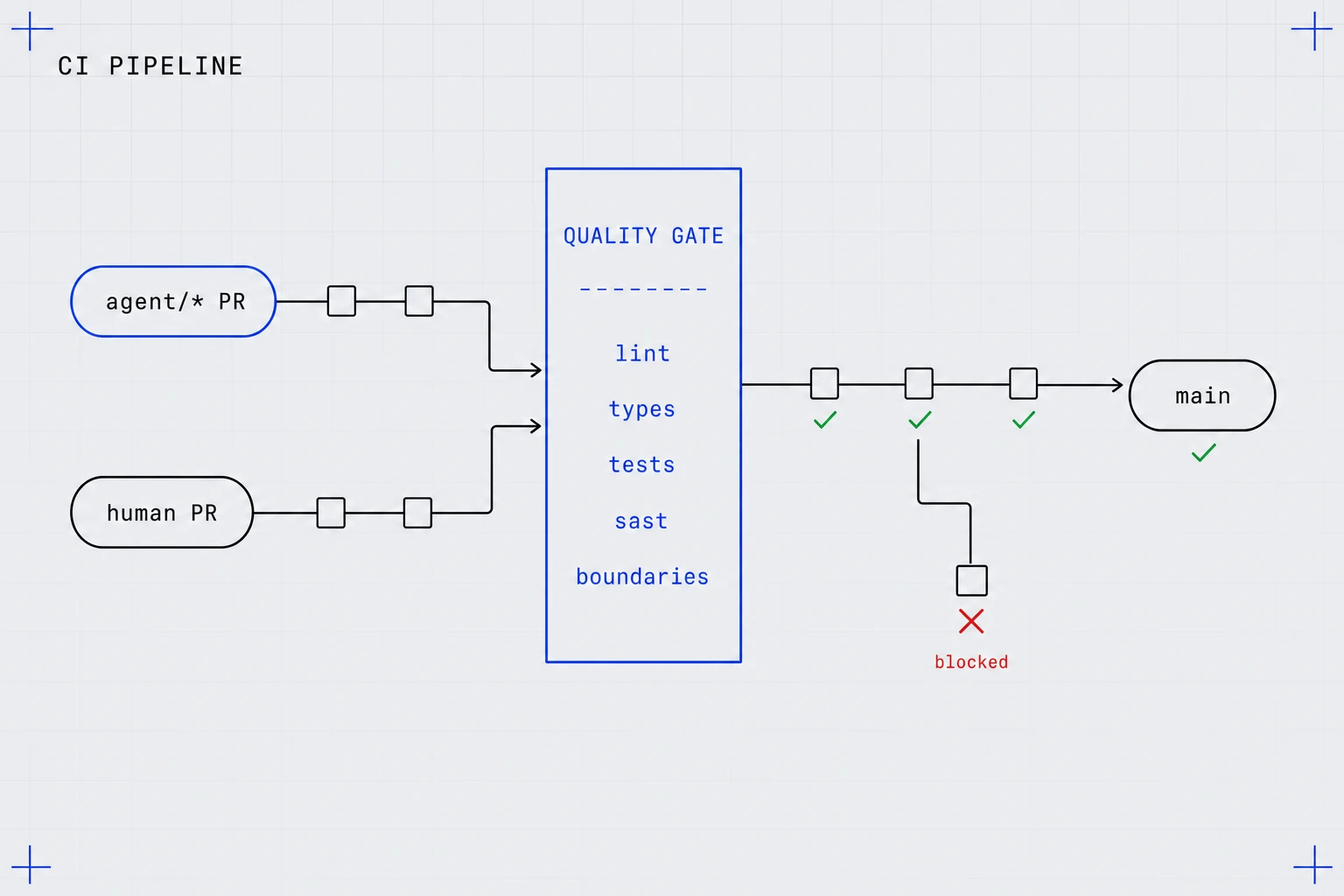
Pre-commit hooks, CI checks, linters, type checkers, SAST, coverage gates, branch protection, required reviews. No new platform — we turn the gates you already pay for into enforceable contracts.
Rules that block the merge
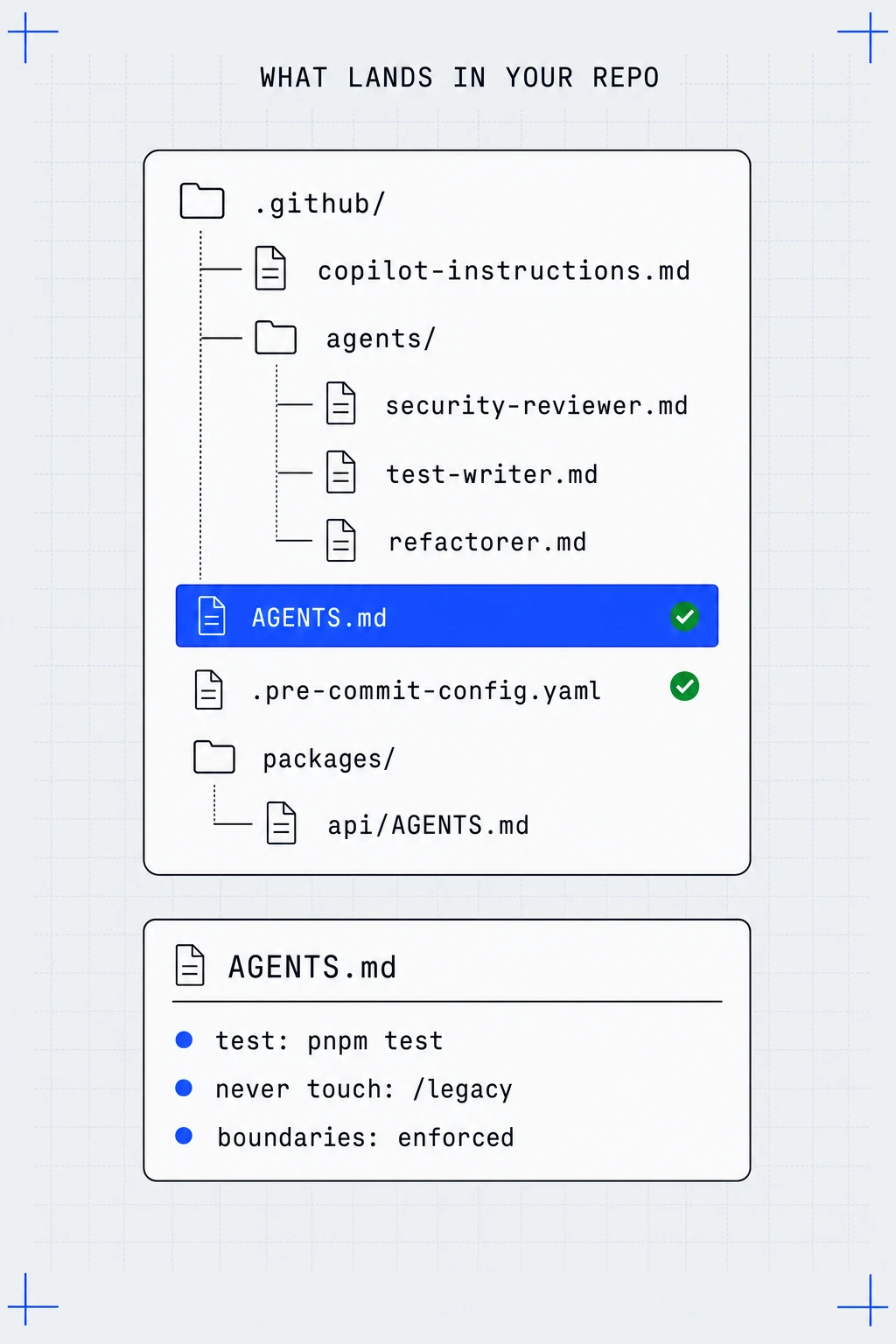
A convention in a doc is a suggestion an agent can ignore. The same rule as a lint rule, an architecture-boundary check, or a failing test is a wall. We convert your conventions into checks that fail CI.
Agents face the human gate
The agent gets no special path. Its PR meets the same required checks your engineers do — so “almost right” fails CI instead of failing in production, and reviewers stop being the safety net.